Reinforcement Learning for Hacking?
Intro
I came across a interesting post on twitter that claims the following:
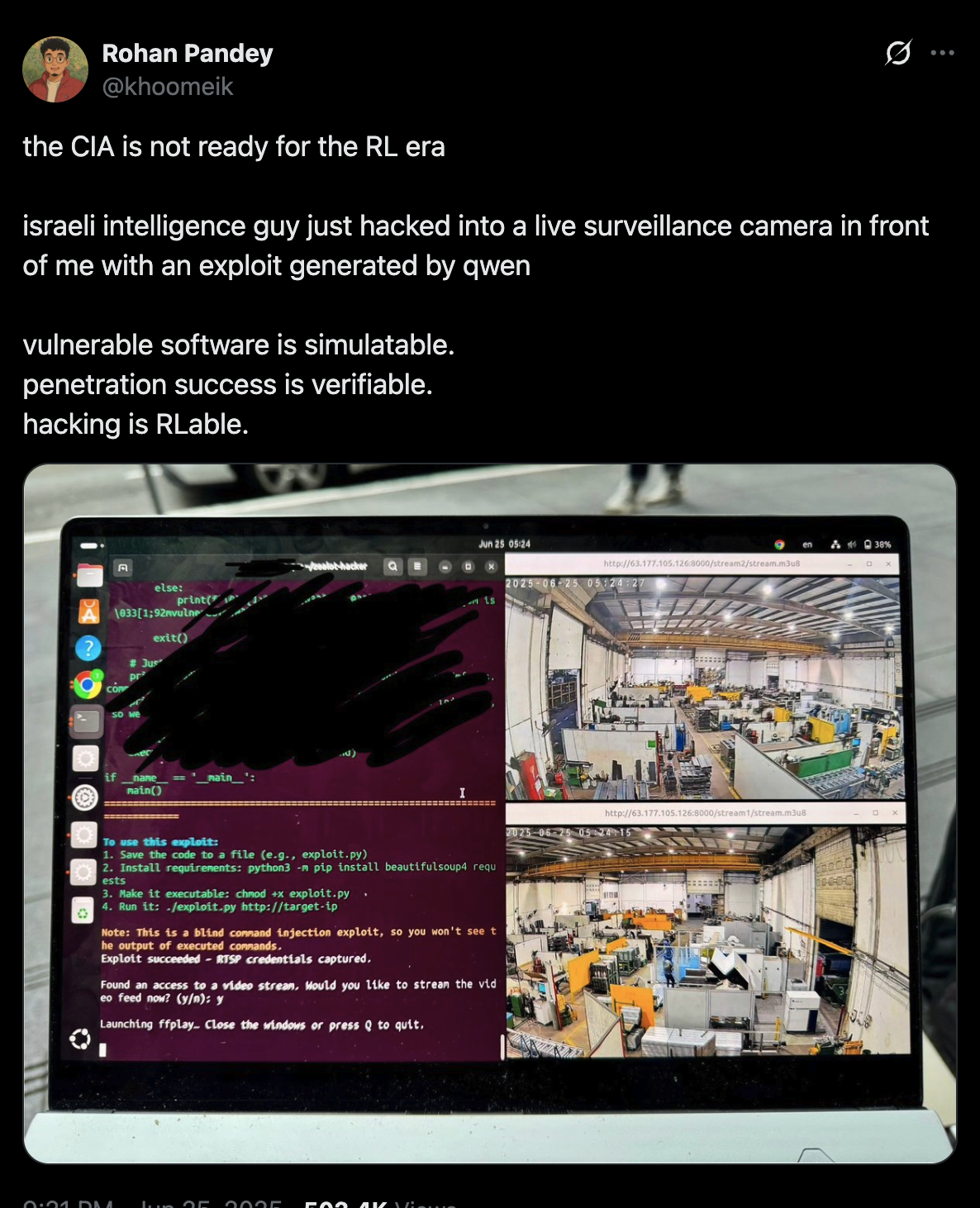
It is an interesting take, but not the hack mentioned, from the screenshot, it looks like a basic script-kiddie hack, brute-forcing credentials on an exposed RTSP camera (rtsp://[username:password@]ip_address:port/path).
Still, the bigger question behind it is interesting:
- vulnerable software is simulatable.
- penetration success is verifiable.
- hacking is RLable.
More importantly, the assertion that vulnerable software is simulatable begs and exploitation success is verifiable suggests we could apply RL to vulnerability research. But this claim requires much deeper understanding from first principles to determine if vulnerability research can truly be solved through RL.
Science of a Vulnerability
If you ask a top security researcher how they find bugs in complex software like Chrome’s V8 engine, you’ll get the same vague answers Cristiano Ronaldo gives about scoring goals: “hard work, practice, experience, mindset.” You won’t get the real answer about what happens inside their brain and body when they spot a vulnerability or hit a goal, because it’s tacit knowledge learned through years of experience.
But here is my attempt to hypothize what vulnerability research actually is:
Vulnerability research is recursively understanding software by processing code and documentation, forming highly abstract concepts in memory similar to state machines, then recursively applying reasoning to these abstract concepts to find weird states we call vulnerabilities.
The recursive nature is crucial both for identification of weird state machines and for processing the information itself. To understand V8 code, you need to understand JavaScript engines. To understand JavaScript engines, you need to understand compilers. To understand compilers, you need to understand computer architecture. And so on.
A similar recursive loop applies while identifying a bug. Once you have the understanding and abstract concepts, you apply recursive reasoning in multiple layers. A type confusion could allow remote code execution, but to find a type confusion, you need to understand how type confusion works, then reason about the code to find where type assumptions can be violated. And so on.
Can we do RL powered vulnerability research?
Now that we’ve defined what vulnerability research entails, let’s examine the prospects of applying reinforcement learning to this domain.
For successful application of RL to vulnerability research, there are two critical requirements:
- Environment that can simulate “real” vulnerabilities
- Good feedback signals (rewards) for trajectories that lead to vulnerability discovery
At first glance this seems doable, to create an environment with good signals, we could harvest all Chromium security issues, generate training data, and perform something like GRPO (Group Relative Policy Optimization) for successful vulnerability identification compared against the oracle of original bugs. We’d have both a simulated environment and grounded reward signals.
But there are fundamental caveats that make this approach less promising than it initially appears.
Caveat 1: Variant Analysis
This is not a caveat but, I argue that if we know what vulnerability to simulate, then you don’t need an RL-trained hacking LLM, you could just use Gemini 5 or Claude 5 to find that vulnerability. These models would likely be able to reason through it as a side effect of being trained on mathematical reasoning.
Remember that “programs are proofs, and proofs are programs, and a vulnerability is also a proof for a program.” If we’ve already identified the vulnerability class and can simulate it, we’ve essentially solved the hard part. The actual discovery becomes a reasoning task that future general LLMs can likely handle.
This means RL would only be valuable for finding completely novel vulnerability classes , discovering entirely new knowledge rather than variants of known bugs.
Caveat 2: The New Knowledge Problem
Finding a new vulnerability is a completely different beast. It’s like discovering new knowledge in a state machine, the bigger and more complex the state machine, the harder it becomes to find novel vulnerabilities.
Consider a real example: when V8 introduced the new heap sandbox cage, a V8 vulnerability researcher receives this initial prompt: “V8 introduced this heap sandbox cage, bypass the cage.” This represents completely new information, so the researcher has to:
- Dig into design documents and code to completely understand the cage mechanism
- Build mental models of how it constrains memory access
- Start reasoning about the state machine to find ways to escape the cage
- Iterate through countless failed attempts
That single prompt would eventually lead to finding a bypass, but only after the bypass is discovered do we get any reward. The reward signal is incredibly sparse, you might spend weeks or months understanding the system with zero positive feedback until that eureka moment when you find the escape vector.
Isn’t this level of sparse reward would be extraordinarily difficult to simulate and even harder for an RL system to navigate effectively?
Why AlphaProof Succeeded Where RL Hacking Would Fail
The recent Alphaproof breakthrough might illustrates exactly why mathematical theorem proving works for RL while vulnerability research doesn’t.
Its success can be completely attributed to having an incredible environment and feedback loop from Lean programming and the Lean theorem prover. You get immediate feedback on whether the formal method you provided as proof is correct, and then RL systems like AlphaGo can handle the remaining search task.
In my opinion, VR has no immediate feedback. It would be hard to provide a better feedback loop for finding completely new vulnerabilities. Most of the exploration is useless, until a point where weird machine appears. I would argue that finding a needle in haystack is where RL might fail.
That doesn’t mean this problem is unsolvable. Problems are soluble.
A potentially better way to solve hacking?
Rather than trying to create “AlphaHacker” with sparse vulnerability rewards, we provbably should focus on improving base LLMs on mathematical reasoning tasks. The side effect will naturally lead to better vulnerability research capabilities.
This mirrors how humans actually learn. We don’t start with tabula rasa before vulnerability identification. We build reasoning capabilities through other methods, mathematics, nature, programming, then apply those skills to security research.
I would argue that LLM that do better on math and programming domains, will naturally transfer to vulnerability research. I will revisit this blog in a year, if its true or not.